As of today, Common Voice has the ability to collect voice data for a specific purpose or use-case. Now, we’re putting it to the test and kicking off data collection for our first, single word target segment. This segment will help us understand how much data is needed to train a machine learning engine on a new voice recognition application in a new language. The data collected will be used to benchmark the accuracy of Mozilla’s open source voice recognition engine, Deep Speech, on multiple languages for a similar task. The tasks we would like to benchmark test are spoken digit recognition, as well as yes and no detection.
To create this target segment we need as many contributors across various languages to record and review the digits zero through nine, as well as the words yes and no.
This target segment will also help improve the testing and training of wake word options for Firefox Voice. By recording and reviewing Hey and Firefox in your language you’ll help generate voice data for Hey Firefox in multiple languages.
How to participate - on your own
Before starting:
Visit the common voice website homepage and check if this limited data set is currently been collected in your language
- If it is, you’ll notice a banner announcing “help create Common Voice’s first target segment” in the homepage
- If it is not, you come back later, new languages will be continuously added! (if you want to collaborate to add your language, see how here)
Step 2
Click on “add your voice”
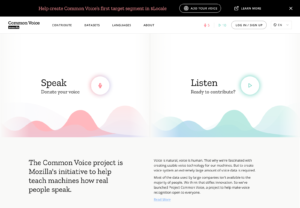
Step 3
Click on the microphone icon
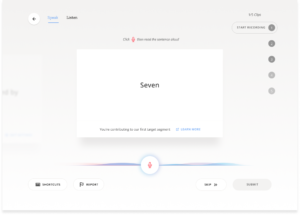
Step 4
Read the sentence out loud (the digits zero through nine, as well as the words yes, no, hey and Firefox)
Step 5
After you read 5 sentences, you will be asked to submit your recording. If you are not happy with your sentences, you will be given the chance to review and re-record them
Step 6
Re-start recording. The target data set will be completed after you read and submit all 14 (single word) sentences.
Review Voice Clips
Step 1
Click on Listen
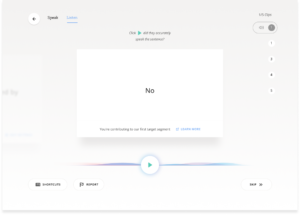
Step 2
Read the word and compare with what you heard. If the voice clip matches the sentence, click “yes.” If the voice clip doesn’t match the sentence, click “no.” (Note: different accents are fine, and encouraged!)
Step 3
Repeat (you will be asked to listen to a maximum of 28 of these single-word recording)
How to participate - with friends (on-line or in-person)
Why not make it an event? Collect your friends (on-line or in-person), and prepare a collective contribution!
You can create your event on the Community Portal and associate it with this campaign. If you need support to carry out an on-line event look here.
Make sure that your language has been added to the target segment before organizing the event!
Workflow
Step 1: Introduce participants to the Common Voice project and explain why the collection of a targeted segment is important (10 minutes)
Introduce the participants to the common voice project and to the data segment experiment. Talk about why it’s important and show them how easy contributing is with just a smartphone. Here are some SLIDES on the common voice project that might be helpful. You can also consider visiting the website voice.mozilla.org together.
Step 2: Have all your participants create an account on their device (10 minutes)
Step 3: Ask your participants to record all 13 short sentences of the targeted voice segment (5 minutes)
After they finished recording the 14 (single word) sentences ask them to announce it.
P.S. If you are using a virtual room, ask your participants to mute while recording.
Step 4: Keep recording other sentences (10 minutes)
Step 5: Review the 14 short sentence (5 minutes)
After they finished reviewing the 14 sentences ask them to announce it.
Step 6: Continue reviewing other people’s voice clips (10 minutes)
Step 7: Keep track of participant progress.
You can easily transform contributions in a game! Make sure your participants have an account set up so everyone can keep track of their contributions using the counter at the top of the website. If you are organizing an on-line event ask people to announce when they pass their targets in a chat or in a shared document.
For example, you can:
- Announce when people have finished recording the 14 single-word sentences
- Announce when people pass 25, 50, 100 clips.
Step 8: Hand out prizes! (5 minutes)
Prizes can be something like sticker